Learning how to use Generalized Linear models in R
Author
Affiliations
Ana Bravo & Tendai Gwanzura
Florida International University
Robert Stempel College of Public Health and Social Work
Published
July 28, 2023
1 Libraries Used
Code
library(katex) # renders math equations library(gt) # publication ready tables library(gtsummary) # extension to publication ready tables library(devtools) # helps with package developmentlibrary(pscl) # maximum likelihood estimation of zero-inflated model for count# library(MEPS) # library for MEPS data, outdated for R version 4.3.0 library(MASS) # fits negative binomial models library(tidyverse) # for wrangling data
2 Introduction
In this presentation, we will be discussing how to use the Generalized Linear Model (GLM) method using count data in the R programming language. We will show how to clean and wrangle the data, show necessary columns to execute our method, discuss assumptions held, showcase the code used to run this GLM, and the interpretation of our output results.
3 What is a GLM?
3.1 lets start with a quick overview of the simple linear regression
As you know, a simple linear regression has two major components: a Y, dependent outcome and an X, which is your independent or your predictor variable. the model looks something like this:
Y_i = \beta_0 + \beta_1X_i + \epsilon where \beta_0 is your intercept and \beta_1 is your slope. A linear model is a function, that us used to fit a data. We often use this method to see the association, or strength in association between two variables of interest:
where:
Y_i is your dependent variable of interest
\beta_0 is your constant terms
\beta_1 is your slope coefficient
and X_i is your independent variable
\epsilon is your random error that cannot be explained.
Code
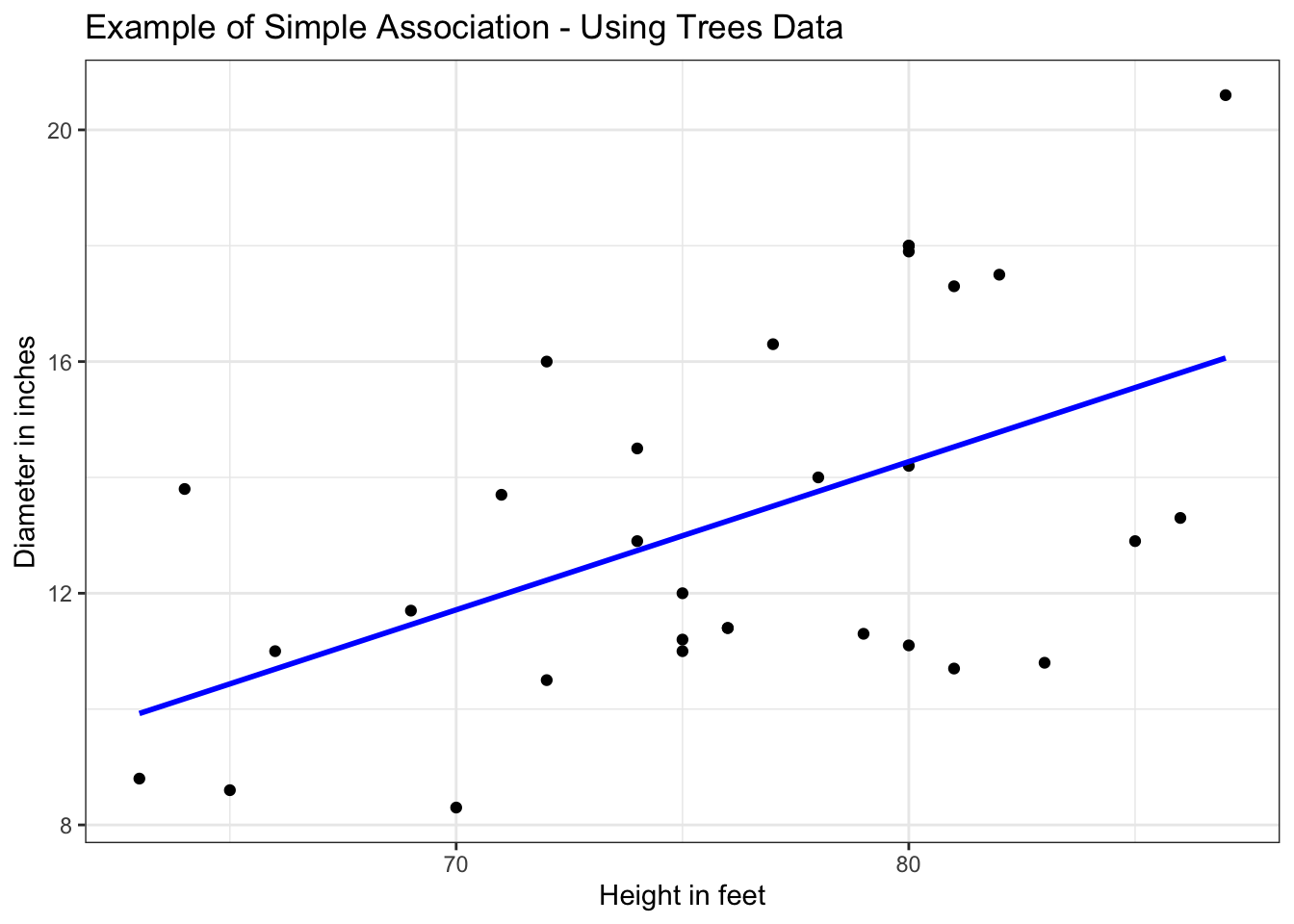
# load data:data(trees)#rename variables:names(trees) <-c("DBH_in","height_ft", "volume_ft3")# simple model:model <-lm(DBH_in ~ height_ft, data = trees)# plot:simple_trees <-#dataggplot(data = trees) +# x and yaes(x = height_ft, y = DBH_in) +#labelslabs(title ="Example of Simple Association - Using Trees Data",x ="Height in feet",y ="Diameter in inches") +# add pointsgeom_point() +# add the lmgeom_smooth(method ="lm", color ="blue", se =FALSE) +# add a simple themetheme_bw()# actual plot: simple_trees
Often you will find this model writen in this form:
E(Y|X) = \beta_0 + \beta_1 + \varepsilon where \beta_0 and \beta_1 are our coefficients that need to be estimated and \varepsilon, or the error term, is used for more complex lines. Our goal is to see the association between an outcome with an exposure.
3.2 Assumptions of a linear equation
Before diving into the generalized models, lets quickly overview the assumptions of linear regression.
Assumption 1: for each combination of independent variable x, y is a random variable with a certain probability distribution.
Assumption 2: Y values are statistical dependent.
Assumption 3: the mean value of Y, for each specific combination of values of X, is a linear function.
Assumption 4: the variance of Y, is the same for any fixed value of X_n
Assumption 5: for any fixed combination of X_n, Y is normally distributed.
Something to note, that in the simple explanation above we are assuming our Y variable (remember one of the points we talked above above? that y holds a specific distribution!) is continuous. So lets talk about our Y variable having a count distribution.
3.3 lets talk about the generalized linear model
the term “generalized” is a big umbrella term used to describe a large class of models. Our response variable y_i is following an exponential family distribution with a mean of u_i which is sometimes non-linear! However McCallagh and Nelder considered them to be linear because our covariate affect the distribution of y_i only through linear combination.
there are three major components of a GLM:
A Random component: which specifies the probability distribution of our response variable
Systematic component: specifies the explanatory variable (x_1 .. x_n) in our model. Or their linear combination (\beta_0 + \beta_1) etc.
a link function: specifies the LINK between the random and systematic components. This helps us figure out our expected values of the response is related to the linear combination of our explanatory variables. for example the link function g(u) = u, which is called an identity function. this models the mean directly. Or, in the case we will talk about today the log of the mean:
log(\pmb{\mu}) = \alpha + \beta_1x_1 + ... B_nx_n + \epsilon Generalized linear function also follows certain assumptions:
the data points are Y_1, Y_2, ..., Y_n are independently distributed (cases are independent)
the dependent variable Y_i does not need to be normally distributed. but it typically assumes a distribution from a family such as binomial, Poisson, multinomial, normal.
GLM does not assume linear relationship between the response variable and explanatory variable but it does assume a linear relationship between the transformed expected response in terms of your link function.
Homogeneity of variance does not need to be satisfied.
Explanatory variables can be nonlinear transformation of some original variable
Parameter estimation uses maximum likelihood estimates (MLE rather than ordinary least squares)
3.4 What is a Poisson Regression?
a Poisson regression models how the mean of a discrete (or we can say count too!) response variable Y depends on our explanatory X variables. Here is a simple look at the Poisson regression:
log \lambda_i = \beta_0 + \beta x_i where the random component: the distribution of Y is the mean of \lambda and the systematic component is the explanatory variable (or your X variables, which can be continuous or categorical) that is linearly associated. Or can be transformed if non-linear, and the link function is the log link stated in the section above.
this Poisson distribution follows a formula that looks as followed:
P(X = x) {\lambda^x e^{-\lambda} \over x!} where
P(X = x) probability of (x) occurrences in a given interval
\lambda mean number of occurrences during interval
x is the number of occurrences desired
e is the base of natural logarithm
An advantage of using GLM over a normal line model is the link function gives us more flexibility in modeling and this model uses the Maximum likelihood estimate. Additionally we can use different inference tools like Wald’s test for logistic and Poisson models.
3.5 important points of Poisson models
we can use this type of link function by using count data. count data can be describes at the number of devices that can access the internet, number of sex partners you have in your lifetime, and the number of individuals infected with a disease.
Poisson is unimodel and skewed to the right, both the mean and the variance are the same. In other words, when the count is larger it tends to be more varied.
if our mew increases the skew decreases and the distribution starts to become more bell shapped. our mean tends to look something like this:
\pmb{\mu} = exp(\alpha + \beta x) = e^\alpha (e^\beta)^x where one unit increase in X has a multiplicative impact on your e^\beta power on the mean. (More on this a little later in the interpretation section!)
3.6 A few last points before we move on
Like with different models in statistics, one must follow the assumptions of a regression, and yes, Poisson has them as well. The assumptions for a Poisson regression are as follows:
Your Y (dependent values) must be count values.
Count values must have a positive integer (or who numbers) (0, 1, 2, 3, ... k). Negative values will not work here.
explanatory variables can be continuous, dichotomous or ordinal
Our count variable must follow a Poisson distribution that is, the mean and variance should be the same. remember this one!
\pmb{\mu} = E(X) = \lambda \sigma^2 = \lambda
when your modeling count data, the link scale is linear. So the effects are additive on the link. While your response scale is nonlinear (this is on the exponent) and so the effects are multiplicative. makes sense? we will work out an example now!
4 Example 1: using GLM for count responses - Using the MEPS data set for 2020
Lets import the built in National Health Care Survery data set from the Medical Expenditure Panel Survey website located here. the code book can also be located here for the 2020 Full year Consolidate data file. the MEPS is the medical expenditure panel survey data, which is a large scale survey about families and individual medical coverage across the United States.
4.1 import MEPS data set
Code
# clean HC2020_clean <-read_csv("/Users/anabravo/Documents/GitHub/R-health-blog/HC2020_clean.csv")# Load data from AHRQ MEPS websitehc2020 =read_MEPS(file ="h224")# lets name a copy of this data set so i don't ruin ithc2020_2 <- hc2020# these variables are upper case, lets turn them lower casenames(hc2020_2) <-tolower(names(hc2020_2))# theres about 14,000 variables. lets keep the ones we want to look athc2020_subset <- hc2020_2 |>select(dupersid,obdrv20, ertot20, rthlth31, adpain42, region31, age20x, racev1x, sex, marry31x, educyr, faminc20, empst31, mcare20)# cleaning names:--------------------------------------------------------------# dupersid = Person ID# obdrv20 = number of office based physician visits in 2020 # ertot20 = emergency rooms visits in 2020# rthlth31 = perceived health status # adpain41 = pain level # region31 = Census region: Northest, midwest, south and west # age20x = Age as of Dec 2020# racev1x = race: white, black, American indiain, Asian, multiple races # sex = sex at birth # marry31x = marital status# educyr = year of ed when entered in MEPS# faminc20 = family total income # empst31 = employment status # mcare20 = Covered by medicare? Yes/no # removing old names because that sub header in columns messes me up sometimes ---names(hc2020_subset) <-NULLnew_names <-c("Person_ID","Nubr_office_visits","Nubr_emergency_visits","Health_status","Pain_Level","Region","Age_as_Dec2020","Race","Is_male","Is_married","Education_lvl","Total_fam_incom","Is_employed","Covered_by_MediCar")names(hc2020_subset) <- new_names# this data set has codes for NA, will switch to NA in R ------------------------HC2020_clean <- HC2020_clean |>mutate(Pain_Level =na_if(Pain_Level, -15)) |>mutate(Health_status =na_if(Health_status, -8)) |>mutate(Region =na_if(Region, -1)) |>mutate(Age_as_Dec2020 =na_if(Age_as_Dec2020, -1)) |>mutate(Is_married =na_if(Is_married,-8 )) |>mutate(Is_employed =na_if(Is_employed, -15)) |>mutate(Education_lvl =na_if(Education_lvl, -15)) |>mutate(Covered_by_MediCar =na_if(Covered_by_MediCar, -1))# also, for ease of interpretation i will dichotomize some variables ------------ HC2020_clean <- HC2020_clean |>mutate(Is_married =ifelse(Is_married ==1, 1, 0)) |>mutate(Is_employed =ifelse(Is_employed ==1, 1, 0)) |>mutate(Is_male =ifelse(Is_male ==1 , 1, 0 )) |>mutate(Covered_by_MediCar =ifelse(Covered_by_MediCar ==1, 1, 0))# i also want to transform some variable using case when -----------------------HC2020_clean <- HC2020_clean |>mutate(Health_status =case_when( Health_status ==1~"Good", Health_status ==2~"Good", Health_status ==3~"Fair", Health_status ==4~"Fair", Health_status ==5~"Poor" )) # clean HC2020_clean_2 --------------------------------------------------------HC2020_clean_2 <- HC2020_clean_2 |># change na valuesmutate(Pain_Level =na_if(Pain_Level, -15)) |>mutate(Health_status =na_if(Health_status, -8)) |>mutate(Region =na_if(Region, -1)) |>mutate(Age_as_Dec2020 =na_if(Age_as_Dec2020, -1)) |>mutate(Is_married =na_if(Is_married,-8 )) |>mutate(Is_employed =na_if(Is_employed, -15)) |>mutate(Education_lvl =na_if(Education_lvl, -15)) |>mutate(Covered_by_MediCar =na_if(Covered_by_MediCar, -1)) |># change married status to binary mutate(Is_married =ifelse(Is_married ==1, 1, 0)) |>mutate(Is_employed =ifelse(Is_employed ==1, 1, 0)) |>mutate(Is_male =ifelse(Is_male ==1 , 1, 0 )) |>mutate(Covered_by_MediCar =ifelse(Covered_by_MediCar ==1, 1, 0)) |>#change healthoutcome categorical for ease of inerpretationmutate(Health_status =case_when( Health_status ==1~"Good", Health_status ==2~"Good", Health_status ==3~"Fair", Health_status ==4~"Fair", Health_status ==5~"Poor" ))# write this data set ---------------------------------------------------------write_csv( HC2020_clean_2,file ="/Users/anabravo/Documents/GitHub/R-health-blog/HC2020_clean_final.csv")
let’s say i want to take a sneak peak at this data set. I will use the gtsummary package to look at the first levels of the data set, and I just want to very simply make this data set interactive by using the opt_interactive() function in the gt package.
Code
HC2020_clean_2 <-read_csv("/Users/anabravo/Documents/GitHub/R-health-blog/HC2020_clean_final.csv")HC2020_clean_2 |>select(Person_ID, Nubr_office_visits, Health_status, Pain_Level, Region, Is_employed, Is_married, Is_employed, Is_male) |>#head(10) |> gt() |>tab_header(title ="Brief view of HC 2020 data set",subtitle ="2020 Data from MEPS website" ) |>opt_interactive(use_search =TRUE,use_highlight =TRUE, use_compact_mode =TRUE,use_resizers =TRUE,use_text_wrapping =FALSE,pagination_type ="jump" )
Brief view of HC 2020 data set
2020 Data from MEPS website
5 Some quick data exploration
Remember what I said earlier about the mean and variance being the same? EDA is important because it might tell us more details about our variable of interest. For this particular question, we might be interested in the number of times an event has occurred. In this case, the number of times someone pay a visit to an office doctor. This data follows everyone for exactly one year.
I am interested in seeing the number of physician office visits in the last year (we can also call this our Y variable)
We are interested in seeing how self-perceived health status (Good, Fair, or Poor), gender (is male, 1 = male, 0 = female), and marital status (married = 0, not married/other categories = 0) is associated with number of doctor visits (our X variables).
Because we are looking at count data, we might find it important to check out the mean and variance of our Y variables. In the case that our Y variable mean and variance are not the same, we might consider some sort of transformation. Transforming a data set can help with the normality of it.
and the variance is about 34.59. We might need to do something with this particular data set but as an example, lets first run a Generalized Linear Model without doing any kind of transformation to the data.
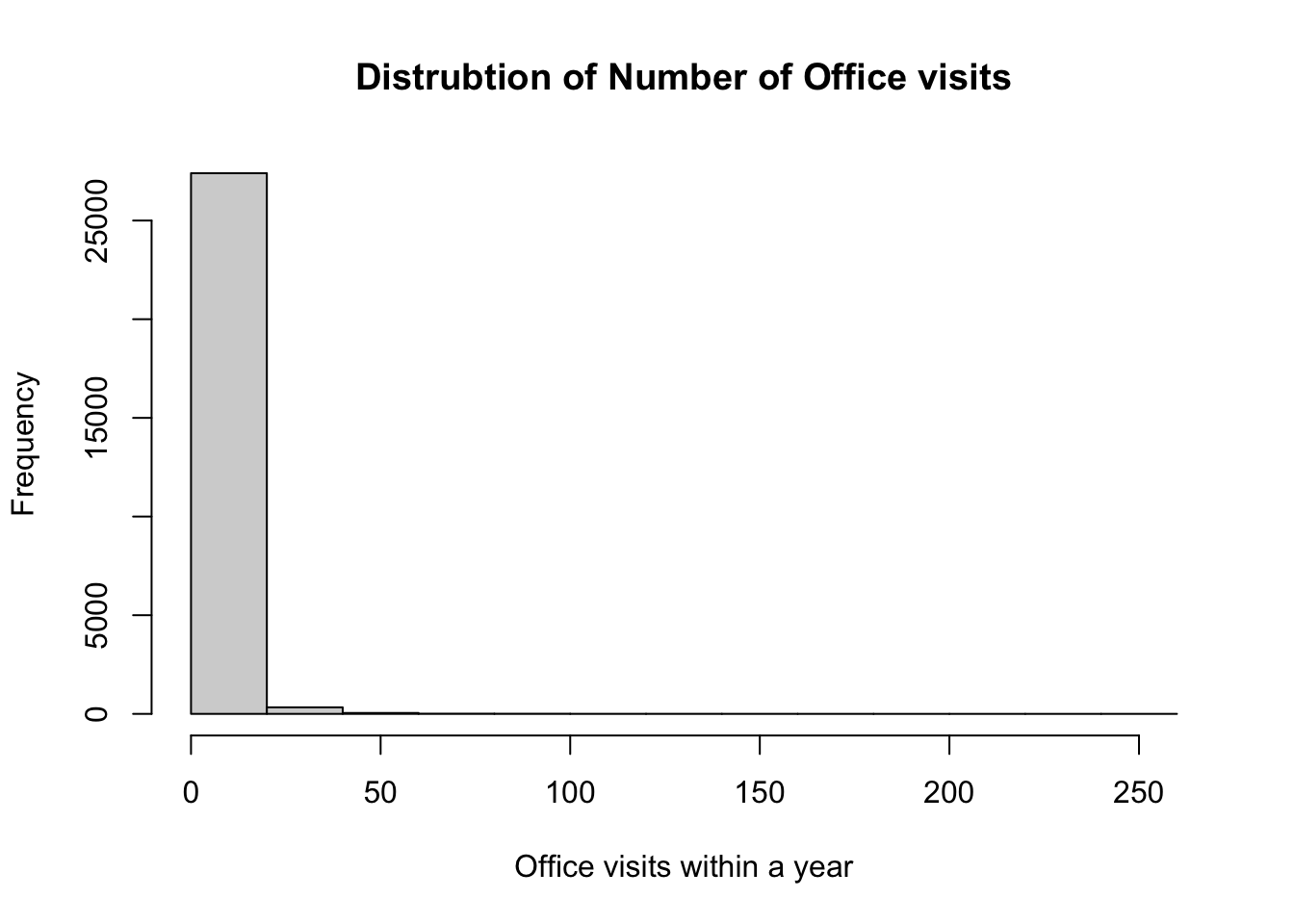
5.2 Checking the distribution of the data
Code
hist(x = HC2020_clean_2$Nubr_office_visits,main ="Distrubtion of Number of Office visits",xlab ="Office visits within a year")
I might also just be interested in the general responses of our y variable of interest:
Code
# I'm just interested in the frequency HC2020_clean_2 |>group_by(Nubr_office_visits) |>summarise(n =n()) |>mutate(Freq = n /sum(n), Freq = scales::percent(Freq)) |>gt() |>opt_interactive(use_search =TRUE,use_highlight =TRUE, use_compact_mode =TRUE,use_resizers =TRUE,use_text_wrapping =FALSE,pagination_type ="jump" )
We might need to check if we have over dispersion in this model. A quick way to check is by diving the residual deviance by our degrees of freedom. IF this value is greater than one, then we can use probably use a negative binomial distribution.
6 How to build a GLM with a Poisson Distribution
The basic core functions of a GLM look something like this: glm(counts ~ outcome + treatment, data = data_set, family = "poisson") which includes:
counts: would be your Y variable
data: where your pulling the data from
~: or an equal sign
outcome + treatment: are your X variables
family: the link or distribution you are following
We are interested in measuring number of visits to a doctors office as a function of perceived health, sex assigned at birth, and marital status.
# build first model PossionModel1 <-glm(Nubr_office_visits ~ Health_status + Is_male + Is_married, data = HC2020_clean_2, family ="poisson")# check summary summary(PossionModel1)
Call:
glm(formula = Nubr_office_visits ~ Health_status + Is_male +
Is_married, family = "poisson", data = HC2020_clean_2)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.340582 0.006745 198.76 <2e-16 ***
Health_statusGood -0.579132 0.007486 -77.37 <2e-16 ***
Health_statusPoor 0.749656 0.014752 50.82 <2e-16 ***
Is_male -0.296143 0.007366 -40.20 <2e-16 ***
Is_married 0.258006 0.007280 35.44 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 164561 on 27182 degrees of freedom
Residual deviance: 151166 on 27178 degrees of freedom
(622 observations deleted due to missingness)
AIC: 199315
Number of Fisher Scoring iterations: 6
this summary gives us the null deviance, which is the total sum of squares, and the residual deviance which is the sum of square errors or the unexplained deviance. We also get the AIC for this model (although AIC is more useful when comparing to other model fits) and we also get the model coefficients for Health status, sex assigned at birth, and marital status. We also get an AIC score of 199315.
lets divide the residual deviance by the degrees of freedom.
1 IRR = Incidence Rate Ratio, CI = Confidence Interval
7 Interpreting Rate Ratio
For this particular data set, we are interested in looking at the number of doctor visits over a year. the coefficient for \beta_1 = -0.579 and is statistically significant. Meaning that perceived health influence the rate of doctors visits. And because it is negative we can figure out by how much. So in other words e^{-.579} = 0.56. This is our rate ratio, the multiplicative increase on doctors visits for those perceived as good health when compared to fair. Because out \beta is < 1, then perceived good health has a protective factor and we can interpret this as:
Perceived good health is associated with a 44% reduction (0.56 - 1 = -0.44) in paid doctors visits in a year.
Lets interpret perceived poor health status when compared to fair. the coefficient for this \beta = 0.74. and is statistically significant. And because it is positive we can figure out by how much and the direction. So in other words e^{.74}) = 2.12.
In other words, those who perceived themselves as in poor health when compared to those perceived in fair health have a 2.12 times more doctors visit. Or we can also say, that perceived poor health is associated with an increase of 112% (2.12 - 1 = 112) increase in doctors visits.
8 How to acount for overdispersion
Remember how we spoke about earlier that this particular model we are fitting is most likely over dispersed? Well, we should try to account for that. Over dispersion means that we may have to much variation in an Poisson regression model. some ways to mediate this is by:
selecting a different random component distribution that can account for this (like negative binomial)
or use a nonlinear and generalize linear mixed model to handle the random effects.
in this case we will go for negative binomial distribution.
9 Negative Binomial Distribution
A negative binomial regression can be used for over-dispersed count data, like mentioned, when the variance exceed the mean. This can be considered like a generalization of the Poisson regression, because it has the same mean structure as Poisson regression but it has an extra parameter to model over-dispersion! Also because of the, the confidence intervals for a negative binomial may be a bit wider when compared to a normal Poisson regression model.
a note about Zero-inflated regressio models: this type of model attempt to account for to many zeros. Zero-inflated models estimate two models at the same time, one for count model and one for excess zeros.
we can also compare our model to a zero inflated model to check for fit:
Code
#this is prob a better fit the negative B PoissonModel2_NB <-glm.nb(Nubr_office_visits ~ Health_status + Is_male + Is_married, data = HC2020_clean_2)# fit model with log linkPoissonModel3_ZI <-zeroinfl(Nubr_office_visits ~ Health_status + Is_male + Is_married, data = HC2020_clean_2, dist ="poisson")#summary analysissummary(PoissonModel3_ZI)
Call:
zeroinfl(formula = Nubr_office_visits ~ Health_status + Is_male + Is_married,
data = HC2020_clean_2, dist = "poisson")
Pearson residuals:
Min 1Q Median 3Q Max
-2.0589 -0.9321 -0.6097 0.2278 77.6141
Count model coefficients (poisson with log link):
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.749834 0.006791 257.68 <2e-16 ***
Health_statusGood -0.458558 0.007723 -59.37 <2e-16 ***
Health_statusPoor 0.509537 0.014775 34.49 <2e-16 ***
Is_male -0.134951 0.007602 -17.75 <2e-16 ***
Is_married 0.137874 0.007482 18.43 <2e-16 ***
Zero-inflation model coefficients (binomial with logit link):
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.69247 0.02658 -26.051 <2e-16 ***
Health_statusGood 0.31720 0.02693 11.777 <2e-16 ***
Health_statusPoor -0.97690 0.10643 -9.179 <2e-16 ***
Is_male 0.43617 0.02582 16.890 <2e-16 ***
Is_married -0.34915 0.02694 -12.962 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Number of iterations in BFGS optimization: 13
Log-likelihood: -8.091e+04 on 10 Df
Code
# comparing AIC score of ZB and NBAIC(PoissonModel2_NB, PoissonModel3_ZI)
as suspected, the model PoissonModel2_NB negative binomial, seems to be a better fit.
Let’s go with a negative binomial regression analysis. In this case we will need to utilize the MASS package to estimate negative binomial regression parameters and account for the dispersion in this data set.
1.00 is much better than 5. Also the AIC value for this model is 112172 which is much better than the original model fit we used on model 1. lets fit this model into GT summary:
1 IRR = Incidence Rate Ratio, CI = Confidence Interval
10 Interpretting Males and those who are married in this data set
Our reference group is 0, so for variables Is_male and Is_married the reference group in this case would be females and not married. When your fitting a model, it is very important to double check what is your reference group because different statistical software may default to different reference groups.
Is_male:e^{-0.32} = 0.72, when comparing males to females, identifying as male is associated with a reduction of 28% (0.72 - 1 = -0.28) in doctors visits.
Is_married:e^{.32} = 1.38, when compared married to non-married individuals, being married is associated with a 38% increase (1.38 - 1 = .38) in doctors visit. Or, the married group has a 1.38 times more doctors visit when compared to non-married.
11 Conclusion
Today you learned of the important of linear regression, the benefits of a generalized linear model, and its assumptions what is a Poisson regression and the assumption that need to be satisfied to run this model, the importance of a Poisson regression, how to build a GLM with a Poisson link, how the clean data from MEPS, how to visualize some counts for this data, how to account for over dispersion and how to interpret rate ratio.
Nelder, J. A., and R. W. M. Wedderburn. 1972. “Generalized Linear Models.” Journal of the Royal Statistical Society. Series A (General) 135 (3): 370. https://doi.org/10.2307/2344614.